Sarah's Two Weeks of Dread
In October 2006, a 42-year-old woman — let's call her Sarah, because that's what the case study calls her — went in for a routine mammogram at a clinic in Portland, Oregon. She had no family history of breast cancer. No lumps. No symptoms. She went because her doctor told her to, because that's what responsible 42-year-olds do.
The test came back positive.
Her doctor, to his credit, tried to be reassuring. He told her the mammogram had a sensitivity of about 90% — meaning it catches 90 out of every 100 actual cancers. He told her the false positive rate was around 9%. Sarah did the math the way any reasonable person would: the test is about 90% accurate, I tested positive, therefore I probably have cancer.
She spent two weeks in a state of dread so consuming she later described it as worse than any diagnosis could have been. She called her sister. She drafted a will. She Googled survival rates at three in the morning, which is exactly as therapeutic as it sounds.
The biopsy came back clean. She didn't have cancer. She'd never had cancer. And here's the part that should make you angry: if her doctor had understood the math — really understood it, not just the sensitivity and the false positive rate, but what those numbers actually mean for a patient standing in front of him — he could have told her that her probability of having cancer, even after the positive test, was roughly 10%.1
Not 90%. Not even 50%. Ten percent.
That gap — between the 90% Sarah assumed and the 10% reality — is not a rounding error. It's a chasm that swallows thousands of people every year.

It drives unnecessary biopsies, unneeded surgeries, months of chemotherapy that ravage bodies hosting tumors that would never have caused harm. It is, without exaggeration, one of the most dangerous misunderstandings in modern medicine.2
And it all comes down to a theorem published in 1763 by a dead Presbyterian minister.
The Reverend's Puzzle
Thomas Bayes never published his most famous idea. He worked it out sometime in the mid-1700s, probably in his study in Tunbridge Wells, and then — perhaps sensing that it was either trivially obvious or disturbingly profound — he stuck it in a drawer. After Bayes died in 1761, his friend Richard Price found the manuscript and sent it to the Royal Society, where it was published under the magnificently understated title "An Essay Towards Solving a Problem in the Doctrine of Chances."3
The problem Bayes solved was this: given that something has happened, how do you update your beliefs about what caused it?
That might sound abstract, so let's go back to Sarah. Here's what she knew:
- About 1 in 100 women her age have breast cancer at any given time. This is the base rate, or in Bayesian language, the prior probability. Before any test, before any evidence, this is your starting point: a 1% chance.
- The test catches 90% of actual cancers. If you have cancer, the test will say "positive" 90% of the time. This is the sensitivity, or the true positive rate.
- The test falsely alarms about 9% of the time. If you don't have cancer, the test will still say "positive" 9% of the time. This is the false positive rate.
Now. Sarah tested positive. What's the probability she actually has cancer?
- P(cancer|+)
- Probability of cancer given a positive test (what we want)
- P(+|cancer)
- Sensitivity — the test catches 90% of real cancers
- P(cancer)
- Base rate — 1% of women this age have cancer
- P(+)
- Total probability of testing positive (true + false positives)
Which is elegant, but if your eyes just glazed over, I don't blame you. Let me show you the same thing a different way — the way that actually works on human brains.
Ten Thousand Women Walk Into a Clinic
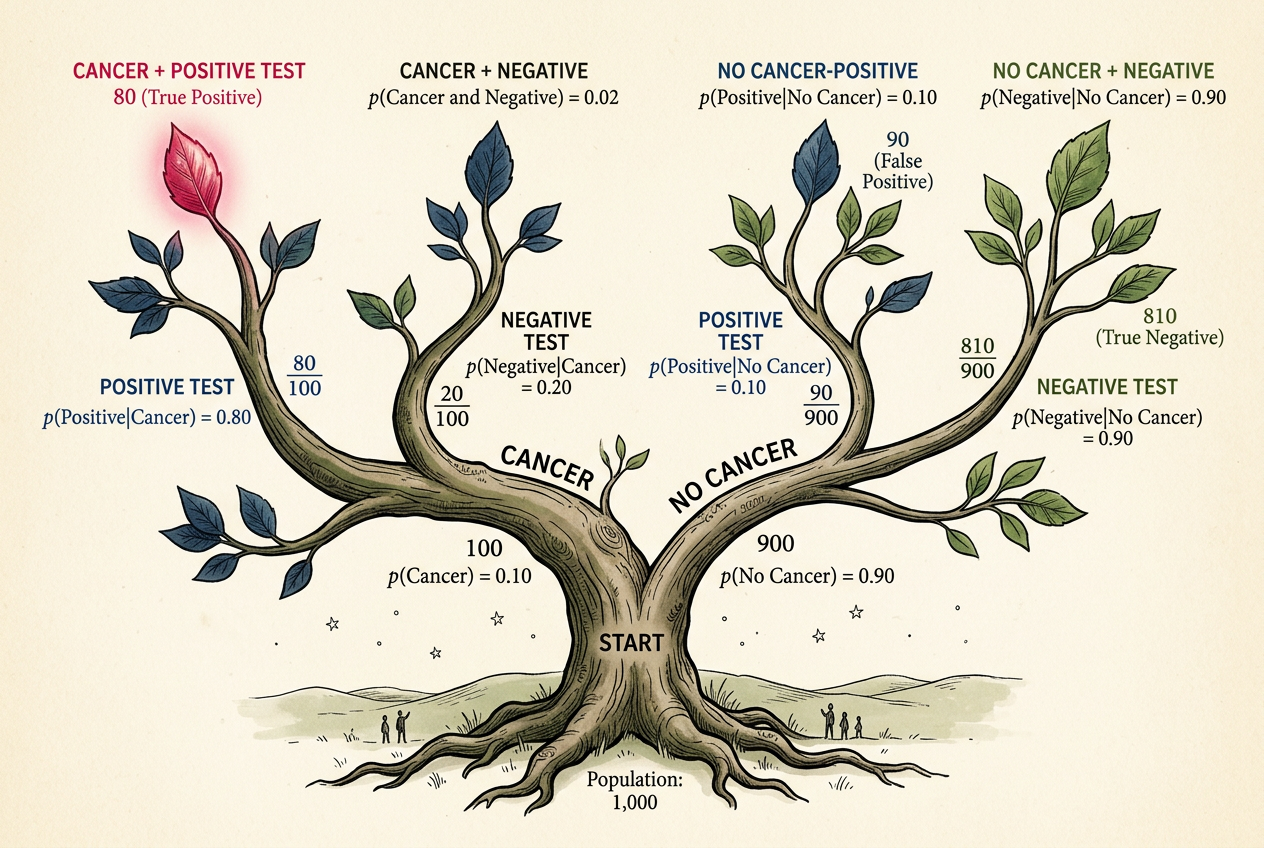
Forget the formula. Imagine 10,000 women, all Sarah's age, all walking into that clinic for a mammogram.
Of those 10,000:
- 100 have cancer (1% base rate).
- 9,900 don't.
Now give them all the test:
- Of the 100 who have cancer, 90 test positive (90% sensitivity). Good.
- Of the 9,900 who don't, 891 test positive anyway (9% false positive rate). Not good.
Total positive results: 90 + 891 = 981.
Of those 981 women clutching a positive test result and spiraling into existential dread, only 90 actually have cancer. That's 90 out of 981, or about 9.2%.
This is the number Sarah's doctor should have told her. This is the posterior probability — your updated belief after seeing the evidence. And it's nowhere near 90%.
Your brain sees "90% accurate" and "positive result" and pattern-matches to "90% chance I'm sick." It simply drops the base rate — the 1% — out of the calculation, as if it were an annoying footnote rather than the single most important number in the entire problem.
Bayesian Probability Calculator
Adjust the inputs and watch how the base rate dominates the result.
Play with this for a minute. Seriously. Drag the base rate slider and watch what happens. When the base rate is low — when the disease is rare — even a very accurate test produces mostly false positives. This isn't a flaw in the test. It's arithmetic. When you're fishing in a pond with very few fish, most of what you catch is going to be boots and old tires.
Now drag the base rate up to 50%. Suddenly the test works beautifully. At a 50% base rate, a positive result from the same test means you're about 91% likely to have the condition. Same test, wildly different meaning — all because of that prior.
The meaning of evidence depends on what you believed before you saw it.
The Prosecutor's Fallacy

In 1999, a solicitor named Sally Clark stood trial in Chester, England, for the murder of her two infant sons. Both had died suddenly — one in 1996, one in 1998. The prosecution's star witness was Sir Roy Meadow, a pediatrician, who testified that the probability of two children in the same family dying of sudden infant death syndrome (SIDS) was 1 in 73 million.4
One in 73 million. That number landed like a bomb in the courtroom. The jury convicted. Sally Clark went to prison.
The number was wrong in at least two ways, but the deeper error was Bayesian. Meadow had calculated the probability of the evidence given innocence — what's the chance two babies die of SIDS if there's no foul play? — and presented it as if it were the probability of innocence given the evidence. These are not the same thing. They are not even close to the same thing.
P(evidence | innocence) ≠ P(innocence | evidence)
The probability of the evidence assuming innocence is not the same as the probability of innocence given the evidence. Confusing the two has sent innocent people to prison.
The Royal Statistical Society took the extraordinary step of issuing a public statement about the case, noting that Meadow's reasoning was fundamentally flawed.5 Clark's conviction was eventually overturned in 2003, but by then she had spent more than three years in prison. She never recovered. She died in 2007, of acute alcohol poisoning, at the age of 42.
The prosecutor's fallacy is base rate neglect wearing a suit and tie. In the mammogram case, your brain ignores the rarity of cancer. In the courtroom, the jury ignores the rarity of the alternative explanation. Same mistake, different stakes. In one case, you lose sleep. In the other, someone loses their freedom.
Your Inner Bayesian Is Terrible (But Trainable)
Here's the thing about base rate neglect: you're not bad at this because you're stupid. You're bad at this because your brain evolved to do something else.
When a rustle in the grass might be a tiger, your ancestors didn't pause to consider the base rate of tiger encounters. They ran. This is sensible survival strategy and terrible probability assessment. Evolution optimized us for fast threat detection, not for careful Bayesian updating. We overweight vivid evidence (a positive test! a rustling bush!) and underweight boring background statistics (the disease is rare, tigers are uncommon here).6
But Bayes' theorem isn't just a formula for medical tests and courtrooms. It's a template for thinking. Every time you encounter new evidence, you are — whether you know it or not — updating a prior belief to form a posterior belief. The question is whether you're doing it well.
Consider: your friend tells you she saw a UFO. How much should this update your belief in alien visitors? It depends entirely on your prior. If you already thought alien visitation was plausible (say, 20%), this evidence might push you to 40%. If you thought it was essentially impossible (0.001%), your friend's testimony — which can be explained by drones, aircraft, atmospheric phenomena, or too much wine — barely moves the needle.
Two people can see the same evidence and reach opposite conclusions without either being irrational. They started in different places.
What Are the Odds?
Estimate the posterior probability for each scenario. How well-calibrated is your inner Bayesian?
The Two Cultures of Uncertainty
There's a deeper philosophical question lurking behind all this, and it's one that statisticians have been arguing about for the better part of a century.
When we say the probability that Sarah has cancer is 10%, what do we mean? Sarah either has cancer or she doesn't — it's not like she's 10% cancerous. There's a fact of the matter, and we just don't know it yet.
This is where the frequentist and Bayesian worldviews diverge. A frequentist says probability is about long-run frequencies: if you ran this test on millions of women like Sarah, about 10% of those who tested positive would have cancer. Probability is a property of the procedure, not of Sarah.
A Bayesian says probability is about degrees of belief: given everything we know, we should be 10% confident that Sarah has cancer. Probability is a property of our knowledge (or ignorance), not of the world.
For Sarah, the distinction is academic. Either way, 10% beats the hell out of 90%, and she can breathe again. But the philosophical disagreement matters in the places where Bayesian thinking truly shines — problems where there's no repeatable experiment, where you need to update beliefs continuously as new evidence arrives.
Should you believe your spouse is cheating? What's the probability a startup succeeds? How confident should you be that a defendant is guilty? These aren't repeatable experiments. There's no long-run frequency to fall back on. There's just evidence, prior beliefs, and the relentless machinery of Bayes' theorem grinding them together.
Bayes doesn't tell you what to believe. It tells you how to change what you believe, in proportion to the evidence. No more, no less. It doesn't tell you what your priors should be — that's on you. But once you have them, it tells you exactly how to react to new information.
The Mammogram Problem, Revisited
In 2009, the U.S. Preventive Services Task Force recommended against routine mammography for women in their 40s — a reversal of previous guidelines.7 The backlash was ferocious. Pundits accused the panel of rationing care. Breast cancer survivors called it dangerous. Politicians called it a death panel.
But the reasoning was Bayesian to its core. Among women aged 40-49, the base rate of breast cancer is low enough that routine screening produces a cascade of false positives. For every life saved by early detection, hundreds of women undergo unnecessary biopsies, further imaging, and weeks of crippling anxiety. Some end up treated for cancers so slow-growing they would never have caused symptoms — a phenomenon called overdiagnosis that is itself a serious medical harm.8
The panel wasn't saying mammograms are useless. They were saying that when you use an imperfect test on a population where the condition is rare, Bayes' theorem guarantees that most of your "detections" will be false. The prior dominates. No amount of sensitivity and specificity can rescue you from a low base rate.
This is the insight that Thomas Bayes left in a drawer, that a dead woman named Sally Clark needed and didn't get, that Sarah's doctor failed to communicate, and that you will now carry with you every time someone tells you a test is "99% accurate."
The test is 99% accurate. But accurate at what? The test's accuracy describes how it performs on sick people and healthy people separately. What you need to know is something different: given that you, specifically, tested positive — given your age, your history, your risk factors, the rarity of the disease — what should you believe now?
Bayes' theorem is the bridge between those two questions. Cross it, and the world looks different. The positive test result doesn't vanish, but it shrinks to its proper size.
The alarming headline about a "90% accurate" AI diagnostic becomes a question: what's the base rate? The confident prosecutor announcing a "one in a million" match becomes a prompt: one in a million compared to what?
You can't unsee it. The prior is always there, quietly dominating the conversation, whether anyone acknowledges it or not. The only question is whether you're paying attention.